Grokking Simplicity Notes

I wanted to put my notes into a separate repository, but then thought that writing the things on my blog is fine, too. Hence the post (and series)’s existence.
Final Verdict
So having read through the book, I can highly recommend it to anyone who is interested in functional programming.
- Newbies can learn a lot from the mentioned techniques and principles.
- People who are a bit familiar with functional programming (like me) still can find other parts to be useful and novel (on architectures and giving technical jargons of functional programming “softer” names).
The book has some parts that answer these two common concerns of non-functional programmers really well:
- Inefficiencies/Performance Issues of Functional Programming
- “Traditional” Layered Architecture versus Onion Architecture
The aims of the book:
- […] about practical uses of Functional Programming.
- […] learn the skills and concepts you can apply today.
Inspired me on a thinking that I found useful: Programming Paradigms are just… groups of programming techniques or tools. Just think about the techniques as some ways to group your code, or make the code clearer. Functional Programming solves some problem better/is more suited in some cases. Object-Oriented Programming also has its own benefits. “There is no silver bullet”, I guess. It is up to us to find the pragmatic way to solve problems.
Chapter 1: Welcome to Grokking Simplicity
What is Functional Programming
I had a “academic” definition for myself. Functional Programming mostly revolves around two concepts: pure functions, and first-class function.
The book gave relevant definitions:
functional programming (FP), noun.
- a programming paradigm characterized by the use of mathematical functions and the avoidance of side effects
- a programming style that uses only pure functions without side effects
But also emphasized that Grokking Simplicity is about practical uses of Functional Programming:
Grokking Simplicity takes a different approach from the typical book about functional programming. It is decidedly about the industrial uses of functional programming.
In Grokking Simplicity, you won’t find the latest research or the most esoteric ideas. We’re only going to learn the skills and concepts you can apply today.
Side Effects
A definition is given within the book:
Side Effects are anything a function does other than returning a value, like sending an email or modifying global state.
I also had more technical jargon for that: Side Effects are the result of a function changing the states that are not in its scope. For example:
# `f` is without side effects since it only returns an increased `a`,
# which is something within `f`'s scope
def f(a: int):
return a + 1
# `g` is with side effects since `send_email` change the state of another mailbox,
# and the mailbox is not within `g`'s scope
def g():
send_email(...)
Actions, Calculations, and Data
Actions depend on when they are called or how many times they are called
[Actions are] anything that depends on when it is run, or how many times it is run, or both
I am not sure what is the difference between “actions” and “impure functions”, and why does the author need to have these three definitions, but probably because I did not read far enough into the book.
Calculations are computations from input to output
Or another term for “pure functions”.
Data is recorded facts about events.
Enough said.
What is Functional Thinking
Functional thinking is the set of skills and ideas that functional programmers use to sole problems with software. This book aims to guide you through two powerful ideas that are very important in functional programming:
(1) distinguishing actions, calculations, and data (2) using first-class abstractions
Chapter 2: Functional Thinking In Action
The chapter skims through a lot of terms that are going to be clarified in details later, so I may revise the writing at a later date.
Chapter 3: Distinguishing Actions, Calculations, and Data
Actions, Calculations, and Data
The author mentioned those three terms again, and I probably got the hang of why did he use “actions” and “calculations” instead of “impure functions” and “pure functions”. The book’s purposes on teaching “functional thinking”, preaching “practical uses of functional programming” is precise the further reason. Having “pure” and “impure” mentioned too early and too frequently may make the book looks academical instead of practical or industrial.
- Actions can hide actions, calculations, and data
- Calculations can be composed of smaller calculations and data
- Data can only be composed of more data
So the author wanted to say that:
- An action can consist of
- Other actions,
- Calculations, and
- Data.
- Calculations can consist of
- Other calculations, and
- Data.
- Data only can consist of
- More data.
I started seeing some kind of logic here, and had a shot in the dark on the “meta reason” of separating actions, calculations, and data. By making sure that we have:
- Actions that read, produce, or change data out of its scope
- Calculations that read, produce, or change data within its scope
- Data that… be data
We have a few layers of “meaning” for our code on separating actions, calculations, and data:
- The lowest layer: the code blocks are “pure” in their definitions, “having one responsibility”
- The immediate layer: they are better structured, better grouped
- The highest layer: they are easier to understand, and easier to debug
More On Actions
How do you use actions if they are so dangerous?
Functional programmers do use actions, but they tend to use them very carefully. The care they put into using them makes up a large part of functional thinking. We’ll address a lot of it in the next few chapters of the book.
My shot in the dark above did not align well with this explanation:
Outside of this book, actions are typically called impure functions, side-effecting functions, or functions with side effects. We call them actions in Grokking Simplicity to avoid ambiguities with specific language features such as JavaScript functions.
A few tricks on managing actions:
- Use fewer actions if possible
- Keep your actions small
- Restrict your actions to interactions with the outside
- Limit how dependent on time an action is
Chapter 4: Extracting calculations from actions
Implicit and explicit, input and output
I found it useful, but hard to put into words, so here is some code:
var total = 0;
function add_to_total(amount) {
console.log("Old total: " + total)
total += amount;
return total;
}
So within add_to_total:
amount: is an explicit outputtotal: is an implicit input and output
And the most important conclusion:
Implicit inputs and outputs make a function and action. […] The trick is to replace the implicit inputs with arguments, and to replace the implicit outputs with return values.
Other
The book is educational, but it does not have to be that real.
After the changes we made, everybody is happy. […]
And don’t forget the CEO. He’s happy because the stock of MegaMart just went up, all thanks to your new free shipping icons. Don’t expect any bonus, though.
Principle: Minimize Implicit Inputs and Outputs
- Implicit inputs are all the inputs that aren’t arguments.
- […] implicit outputs are all of the outputs that aren’t the return value.
However, calculations aren’t the only thing that this principle applies to. Even actions would do well to eliminate implicit inputs and outputs. Even if you can’t eliminate all implicit inputs and outputs, the more you can eliminate, the better.
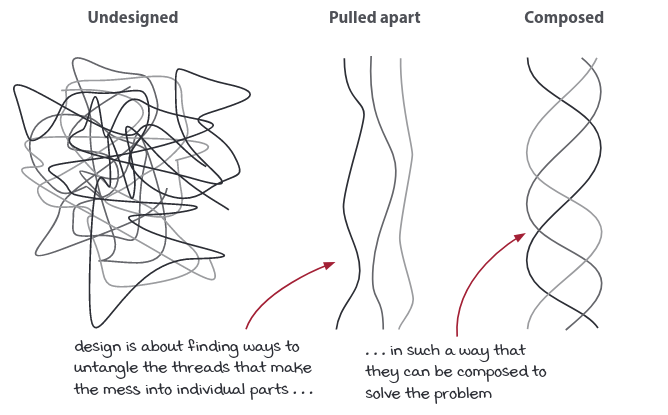
Principle: Design Is About Pulling Things Apart
Bigger, more complex things feel more substantial. But things that are pulled apart can always be composed back together. The hard part is figuring out useful ways to pull them apart.
The benefits of pulled apart code:
- Easier to reuse
- Easier to maintain
- Easier to test
Staying Immutable In A Mutable Language
Categorizing Operations Into Reads, Writes, Or Both
Reads
- Get information out of data
- Do not modify the data
Writes
- Modify the data
The three steps of the copy-on-write discipline:
- Make a copy.
- Modify the copy.
- Return the copy.
Reading for a while, I think I can explain the benefits of “copy-on-write” benefits with this self-made diagram:
[data] --(mutable process)--> [data'] --(mutable process)--> [data''] --> ...
In this mutable process, the data goes through a lot of implicit changes, makes it harder to debug and test.
[data] --(immutable process)--> [data 1] --(immutable process)--> [data 2] --> ...
| |
+---------------> [data] +---------------> [data 1]
In this immutable process, we see explicitly how is the data changed, makes it easier to debug and test.
Reads Into Immutable Data Structures Are Calculations
And also:
- Reads to mutable data are actions
- Writes make a given piece of data mutable
- If there are no writes to a piece of data, it is immutable
- Reads to immutable data structures are calculations
- Converting writes to reads makes more code calculations
Immutable Data Structures Are Fast Enough
I need these points on explaining to people on functional programming and immutable data:
- We can always optimize later
- Garbage collectors are really fast
- We’re not copying as much as we might think at first
- Functional programming languages have fast implementations
Staying Immutable With Untrusted Code
The Rules Of Defensive Copying
Before letting the data enters/leaves the current code base, make sure that they are copied.
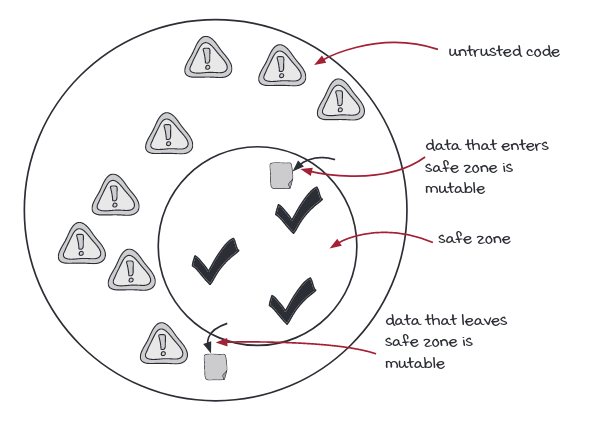
- Rule 1: Copy as data leaves your code
- Rule 2: Copy as data enters your code
Stratified Design: Part 1
What Is Stratified Design?
Stratified design is a technique for building software in layers. Each new layer defines new functions in terms of the functions in the layers below it.
I found stratified design kind of vague, so I searched for another post for explanation and got a good one on that: https://ccd-school.de/2017/06/stratified-design-over-layered-design/
In short, we can look at this picture from the post:
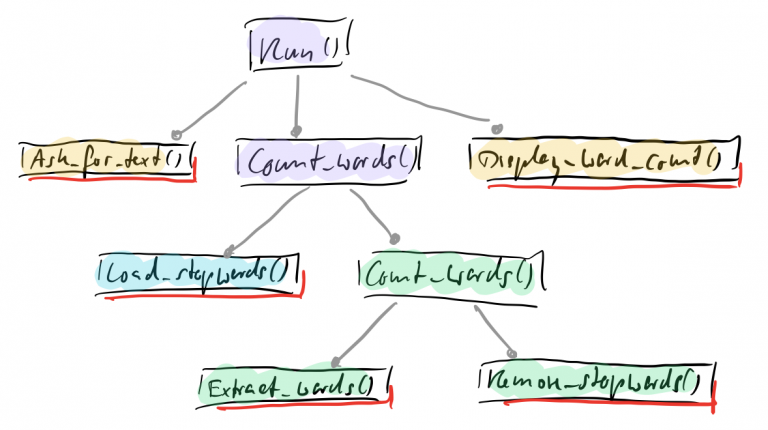
Also, try thinking of the function as “integration units” and “operation units” of “Integration Operation Segregation Principle” also helps:
- Either a method contains exclusively logic, meaning transformations, control structures or API invocations. Then it’s called an Operation.
- Or a method does not contain any logic, but exclusively calls over methods within its code basis. Then it’s called Integration.
Developing Our Design Sense
I found it useful making a table for the inputs and the outputs for the designing process:
| Inputs | Outputs |
|---|---|
| Function Bodies | Organization |
| - Length | - Decide where a new function goes |
| - Complexity | - Move functions around |
| - Levels of detail | |
| - Functions called | |
| - Language features used | |
| ————– | ————– |
| Layer Structure | Implementation |
| - Arrow length | - Change an implementation |
| - Cohesion | - Extract a function |
| - Level of detail | - Change a data structure |
| ————– | ————– |
| Function Signatures | Changes |
| - Function name | - Choose where new code is written |
| - Argument names | - Decide what level of detail is appropriate |
| - Argument values | |
| - Return value |
Patterns Of Stratified Design
- Pattern 1: Straightforward Implementation
- Pattern 2: Abstraction Barrier
- Pattern 3: Minimal Interface
- Pattern 4: Comfortable Layers
Pattern 1: Straightforward Implementation
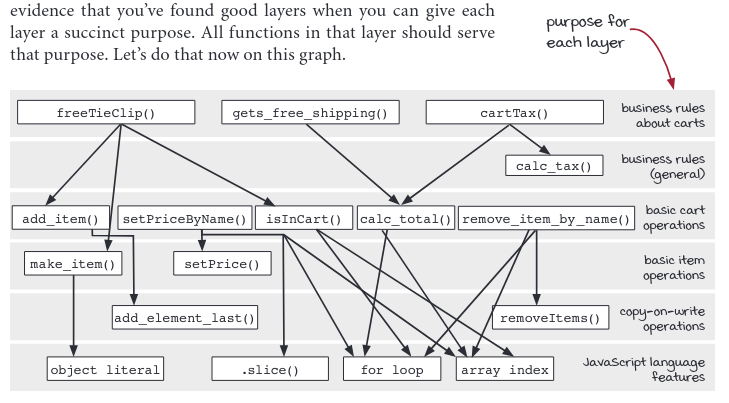
- Straight forward implementations call functions from similar layers of abstraction
- All functions in a layer should serve the same purpose
- Straightforward code solves a problem at a single level of detail
- Stratified design helps us target a specific level of detail
- The call graph gives us a rich source of clues about levels of detail
- Extracting out a function makes a more general function
- More general functions are more reusable
- We don’t hide the complexity
Stratified Design: Part 2
Pattern 2: Abstraction Barrier
- Abstraction barriers hide implementations
An abstraction barrier is a layer of functions that hide the implementation so well that you can completely forget about how it is implemented even while using those functions.
- The abstraction barrier lets us ignore details
When to use (and when not to use!) abstraction barriers
- To facilitate changes of implementation
- To make code easier to write and read
- To reduce coordination between teams
- To mentally focus on the problem at hand
The key thing to remember about abstraction barriers is that it’s all about ignoring details. Where is it useful to ignore details? What details can you help people ignore? Can you find a set of functions that, together, help you ignore the same details?
Pattern 3: Minimal Interface
The minimal interface pattern states that we should prefer to write new features at higher levels rather than adding it to or modifying lower levels.
There are many reasons to keep the abstraction barrier minimal:
- If we add more code to the barrier, we have more to change when we change the implementation
- Code in the barrier is lower level, so it’s more likely to contain bugs
- Low-level code is harder to understand
- More functions in an abstraction barrier mean more coordination between teams.
- A larger interface to our abstraction barrier is harder to keep in your head.
Pattern 4: Comfortable Layer
The comfort pattern gives us a practical test of when to stop striving for the other patterns (and also where to start again). We ask ourselves, “Are we comfortable?” If we are comfortable working in the code, we can relax on design. Let the for loops go unwrapped. Let the arrows grow long and the layers meld into one another.
First-class Functions: Part 1
Code Smell: Implicit Argument In Function Name
If you are referring to a value in the body of a function, and that value is named in the function name, this smell applies.
Characteristics:
- There are very similar function implementations.
- The name of the function indicates the difference in implementation
The code smell can be seen in this sample code:
function setPriceByName(cart, name, price) {
var item = cart[name];
var newItem = objectSet(item, 'price', price);
var newCart = objectSet(cart, name, newItem);
return newCart;
}
function setQuantityByName(cart, name, quantity) {
var item = cart[name];
var newItem = objectSet(item, 'quantity', quantity);
var newCart = objectSet(cart, name, newItem);
return newCart;
}
function setShippingByName(cart, name, shipping) {
var item = cart[name];
var newItem = objectSet(item, 'shipping', shipping);
var newCart = objectSet(cart, name, newItem);
return newCart;
}
Refactoring: Express Implicit Argument
[…] Here are the steps:
- Identity the implicit argument in the name of the function
- Add explicit argument
- Use new argument in body in place of hard-coded value
- Update the calling code
function setFieldByName(cart, name, field, value) {
var item = cart[name];
var newItem = objectSet(item, field, value);
var newCart = objectSet(cart, name, newItem);
return newCart;
}
Refactoring: Replace Body With Callback
- Identify the before, body, and after sections.
- Extract the whole thing into a function.
- Extract the body section into a function passed as an argument to that function.
// before
function withLogging() {
try {
saveUserData(user);
} catch (error) {
logToSnapErrors(error);
}
}
withLogging();
// after
function withLogging(f) {
try {
f();
} catch (error) {
logToSnapErrors(error);
}
}
withLogging(function () {
saveUserData(user);
});
Personal Notes
I can imagine a newbie getting confused, even with just “first-class functions” and “higher-order functions”. The concept kind of blew my mind on my first time knowing it, too.
First-class Functions: Part 2
Higher-order Function
When you do come up with a solution using a higher-order function, compare it to the straightforward solution. Is it really better? Does it make the code clearer? How many duplicate lines of code are you really removing? How easy would it be for someone to understand what the code is doing? We mustn’t lose sight of that.
Bottom line: These are powerful techniques, but they come at a cost. They’re too little too pleasant to write, and that blinds us to the problem of reading them. Get good at them, but only use them when they really make the code better.
Functional Iteration
I found nothing really new here with map, filter, and reduce, but I can
totally imagine how useful are them to people who are new to Functional
Programming.
Chaining Functional Tools
Stream Fusion
I found this useful, as some code that I wrote is similar to the before, and
I rarely think of writing them like after.
Two
map()steps in a row:
// before
var names = map(customers, getFullName);
var nameLengths = map(customers, stringLength);
// after
var nameLengths = map(customers, function(customer) {
return stringLength(getFullName(customer));
});
Two
filters()steps in a row
// before
var goodCustomers = filter(customers, isGoodCustomer);
var withAddresses = filter(customers, hasAddress);
// after
var withAddresses = filter(customers, function(customer) {
return isGoodCusomter(customer) && hasAddress(customer);
});
map()step followed byreduce()step
// before
var purchaseTotals = map(purchases, getPurchaseTotal);
var purchaseSum = reduce(purchaseTotal, 0, plus);
// after
var purchaseSum = reduce(purchases, 0, function(total, purchase) {
return total + getPurchaseTotal(purchase);
});
Again, this is an optimization. It will only make a difference if that is the bottleneck. In most cases, it is much clearer to do things in multiple steps, since each step will be clear and readable.
Debugging Tips For Chaining
- Keep it concrete
[…]. Be sure to use clear names in your code so that you don’t lose track of what is what. Variable names like
xandakeep things short, but they have no meaning. Use names to your advantage.
- Print it out
[…]. […] insert a print statement between two steps, and then […] run the code. It’s a good reality check to make sure each step is working as expected.
- Flow your type
Functional Tools for Nested Data
It is a function called update which is Clojure-inspired (?). Basically, my
implementation of the function looks like this:
function update(obj, key, value) {
const newObj = { ...obj }
newObj[key] = value
return newObj
}
I got lazy and did not implement the multiple-key version, but you got the idea, I think.
Isolating Timelines
Timelines are sequences of actions that can run simultaneously. They capture what code runs in sequence and what runs in parallel.
I got a related core idea on concurrent programming bugs after reading the section on reassigning from SICP:
let balance = 10;
function deposit(amount) {
balance = balance + amount;
}
function withdraw(amount) {
balance = balance - amount;
}
Suppose that deposit and withdraw is called in the same time:
deposit(20)
withdraw(30)
While our preferred result is 0 (10 + 20 - 30), 30 (10 + 20) and -20
(10 - 30) are possibilities.
Our functions look simple enough, but in reality, each is doing a few things:
- Get global balance
- Calculate new balance
- Change global balance to new balance
Which are three separate actions (or two actions, and one calculation; determining what are the actions and what is the calculation is left to the reader; the terminology is temporarily different here, please bear with it).
In the end, we have six actions:
- Get global balance 1
- Calculate new balance 1 (+ amount)
- Change global variable to new balance 1
- Get global balance 2
- Calculate new balance 2 (- amount)
- Change global variable to new balance 2
And the final result is a permutation of those six actions. For example:
- Get global balance 1: 10
- Calculate new balance 1 (+ 20): 30
- Change global variable: 30
- Get global balance 2: 30
- Calculate new balance 2 (- 30): 0
- Change global variable 2: 0
We get our preferred result, but suppose we have another sequence:
- Get global balance 1: 10
- Get global balance 2: 10
- Calculate new balance 1 (+ 20): 30
- Change global variable to new balance 1: 30
- Calculate new balance (- 30): -20
- Change global variable to new balance 2: -20
Did you see how that goes? async functions encounter errors for the same
reason: they have smaller “actions” within, and the final sequence is hardly
determined.
Principle: In An Asynchronous Context, We Use A Final Callback Instead Of A Return Value As Our Explicit Output
function async(a, cb) {
...
// b: final result
cb(b);
}
I had some on why should we do it, but I could not recall the ideas. I am going to revisit this in a later time.
Sharing Resources Between Timelines
The author walked through a queue implementation in JavaScript and it looked… really cool. The overall principle is: to ensure ordering in execution, put the actions into a queue.
function Queue(worker) {
var queue_items = [];
var working = false;
function runNext() {
if (working) return;
if (queue_items.length === 0) return;
working = true;
var item = queue_items.shift();
worker(item.data, function(val) {
working = false;
setTimeout(item.callback, 0, val);
runNext();
});
}
return function(data, callback) {
queue_items.push({
data: data,
callback: callback || function() {},
})
}
}
Coordinating Timelines
The author introduced Cut, and JustOnce, which also are cool primitives that we
can use to think of when programming multi-threaded (or multi-processed):
function Cut(num, callback) {
var num_finished = 0;
return function() {
num_finished += 1;
if(num_finished === num)
callback();
}
}
function JustOnce(action) {
var alreadyCalled = false;
return function(a, b, c) {
if(alreadyCalled) return;
alreadyCalled = true;
return action(a, b, c);
}
}
Reactive and Onion Architectures
Reactive Architecture
Its main organizing principle is that you specify what happens in response to events. It is very useful in web services and UIs.
- In a web service, you specify what happens in response to web requests.
- In a UI, you specify what happens in response to UI events such as button clicks. These are usually known as event handlers.
Decouples effects from their causes
Separating the causes from their effects can sometimes make code less readable. However, it can also be very freeing and let you express things much more precisely.
Treats a series of steps as pipelines
Creates flexibility in your timeline
ValueCells simply wrap a variable with two simple operations. One reads the current value (val()). The other updates the current value (update()). […] Watchers are handler functions that get called every time the state changes.
function ValueCell(initialValue) {
var currentValue = initialValue;
var watchers = [];
return {
val: function() {
return currentValue;
},
update: function(f) {
var oldValue = currentValue;
var newValue = f(oldValue);
if (oldValue !== newValue) {
currentValue = newValue;
forEach(watchers, function(watcher) {
watcher(newValue);
});
}
},
addWatcher: function(f) {
watchers.push(f);
}
};
}
There’s more than one name for the watcher concept. No name is more correct than the others. You may have heard these other names:
- Watchers
- Listeners
- Callbacks
- Observers
- Event Handlers
The equivalent to
ValueCellsare found in many functional languages and frameworks:
- In Clojure: Atoms
- In Elixir: Agents
- In React: Redux store and Recoil atoms
- In Haskell: TVars
- Decouples effects from their causes
Decoupling manages a center of cause and effect

[…] high growth is the problem that decoupling solves. It converts the growth operation from a multiplication to an addition. We need to write five causes and separately write four effects. That’s 5 + 4 places instead of 5 * 4. If we add a cause, we don’t need to change the effects. That’s what we mean when we say the causes are decoupled from the effects.
[…] Sometimes, the clearest way to express a sequence of actions is by writing them in sequence, line by line. If there’s no center, there’s no reason to decouple.
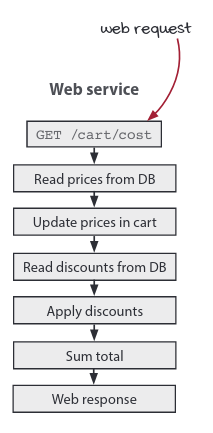
- Treat series of steps as pipelines
Reactive architecture lets us build complex actions out of simpler actions and calculations. The composed actions take the form of pipelines. Data enters in the top and flows from one step to the next. The pipeline can be considered an action composed of smaller actions and calculations.
If you’ve got a series of steps that need to happen, where the data generated by one step is used as the input to the next step, a pipeline might be exactly what you need.
To be hones, I was not sure what was the correlation of reactive architecture and creating data pipelines.
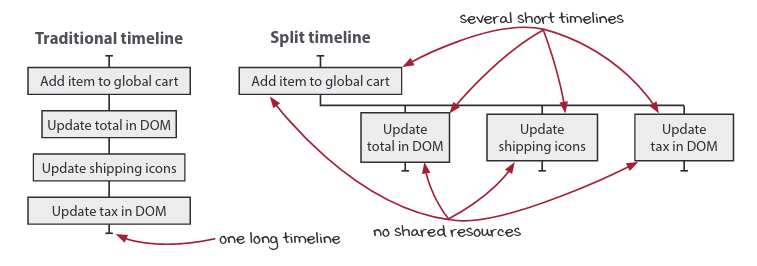
- Flexibility in your timeline
Reactive architecture can also give you flexibility in your timeline, if that flexibility is desired. Because it flips the way we typical define ordering, it will naturally split the timelines into smaller parts.
Onion Architecture
The onion architecture is a way to structure services and other software that have to interact with the world. As the name suggests, the architecture is drawn as a set of concentric layers, like an onion.
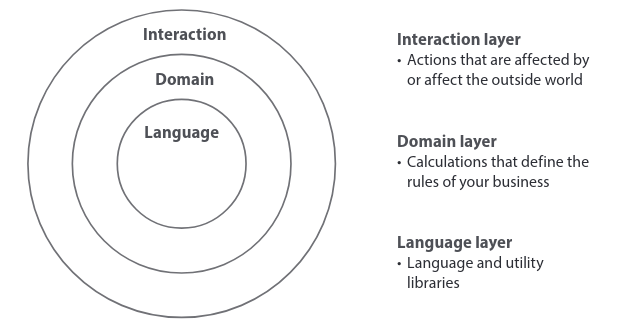
The onion architecture is not specific about what layers you have, but they generally follow these three large groupings. Even this simple example shows the main rules that make it work well in functional systems. Here are those rules:
- Interaction with the world is done exclusively in the interaction layer
- Layers call in toward the center
- Layers don’t know about layers outside of themselves
The onion architecture aligns very well with the action/calculation division and stratified design we learned in part 1. We will review those, and see how we can apply the onion architecture to real-world scenarios.
Traditional Layered Architecture versus Onion Architecture
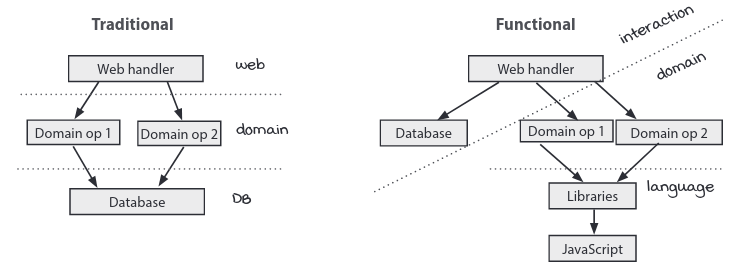
In [layered architecture], the database (DB) is the foundation at the bottom of everything. The domain layer is built out of, among other things, operations on the DB. The web interface translates web requests into domain operations.
[…] The database is mutable. That’s the point of it. But that makes any access to it an action. Everything on the path to the top of the graph will necessarily be an action, including all of the domain operations. […] [we] would rather extract calculations from the actions. [We] want a clean separation, to the point of building the entire business and domain logic in terms of calculations. The database is separate (though important). The action at the top ties the domain rules to the state in the database.
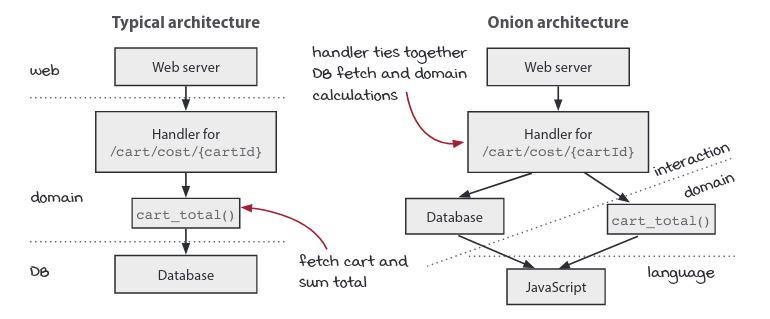
In the typical architecture, the layers are clearly stacked. A web request is routed to a handler. The handler accesses the database. Then it returns the response to the top-most layer, which sends it back to the client.
In the onion architecture, we have to turn our heads to see the layers, since the dividing line is skewed. The web server, handler, and database all belong in the interaction layer.
cart_total()is a calculation that describes how to sum the prices of the cart into a total. It does not know where the cart comes from (from the database or somewhere else). The web handler’s job is to provide the cart by fetching it from the database. Thus, the same work is done, but in different layers. The fetching is done in the interaction layer and the summing in the domain layer.
Onion Architcture “In Real Life”
Here comes my favorite passage that embodies the goodness of the book: a lot of idealized and useful techniques that are combined with practical “real life” advices. The original title for the section is “Analyze Readability and Awkwardness”, but I found my own title to be more on point.
[…] Sometimes the benefits of a particular paradigm are not worth the cost. This includes choosing to implement parts of your domain as calculations. Even though it’s totally possible to implement your domain entirely as calculations, we have to consider that sometimes, in a particular context, an action is more readable than the equivalent calculation.
Readability depends on quite a few factors. Here are some major ones:
- The language you are writing in
- The libraries you are using
- Your existing legacy code and code style
- What your programmers are accustomed to
The image of the onion architecture we’ve seen here is an idealized view of a real system. People can easily tie themselves in knots trying to reach that ideal of 100% purity of the onion architecture vision. However, nothing is perfect. Part of your role as architect is to trade off between conformance to the architecture diagram and real-world concerns.
The Functional Journey Ahead
Big Takeaways
- There are often calculations hidden in your actions
- Higher-order functions can reach new heights of abstraction
- You can control the temporal semantics of your code
The Ups And Downs Of Skill Acquisition
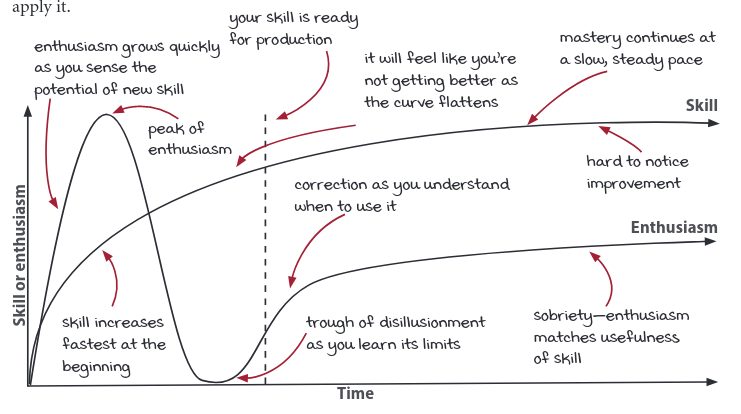
Whenever we learn a new skill, we go through a similar process to make the skill our own.
- At first, we burn with the pleasure of new-found power. We seek to apply it everywhere, to play with our new toy.
- […] we learn the limits of the new skill.
- Gradually, we understand where to apply the skill.
- We learn how it interacts with the other things we know.
- And we learn when not to apply it.